
Temps de lecture : 30 minutes | Niveau : Intermédiaire | Dernière mise à jour : 04 janvier 2026 | Auteur : Franck Jeannot | AC852
Ce guide vous montre comment fine-tuner votre propre modèle pour améliorer la précision sur la génération de diagrammes Mermaid.
📑 Sommaire
1. Pourquoi fine-tuner pour Mermaid ?
Les LLMs généralistes (Open AI GPT, Anthropic Claude, Google Gemini/Gemma, Qwen…etc) génèrent souvent du code Mermaid syntaxiquement incorrect. Pourquoi ? Parce que Mermaid représente une fraction infime de leurs données d’entraînement.
Problèmes typiques :
- ❌ Flèches avec syntaxe invalide (
->>au lieu de-->) - ❌ Noeuds référencés mais jamais déclarés
- ❌ Mélange de syntaxes entre types de diagrammes
- ❌ Guillemets mal échappés dans les labels
- ✅ Générer un dataset synthétique de qualité
- ✅ Fine-tuner (cloud Gemini/Gemma :VERTEX AI, Local GPU: Phi-4, Local CPU: Qwen2.5-1.5B (limité…) )
- ✅ Valider automatiquement les diagrammes générés
- ✅ Atteindre de meilleurs taux de compilation contre ~70% pour les modèles de base en général (statut Décembre 2025 sur base des modèles disponibles).
Le projet diagram-llm2 aide à réduire ces problèmes (fork basé sur diagram-llm )
2. Prérequis
🔧 Prérequis techniques
-
- Python 3.12+ installé sur votre machine recommandé
- Clé API Google AI Studio (gratuit) pour Gemini et Gemma mais avec des limites fortes, voir https://github.com/blue101010/diagram-llm2/blob/main/gemini_fine_tune/models_limits_free.json pour des tests initiaux
- projet VERTEX AI en cas d’usage de modèles Google Cloud (attention, l’API confirme This API method requires billing to be enabled)
- ~10 Go d’espace disque local (modèles locaux)
- Familiarité avec la syntaxe Mermaid de base
Fine Tuning et Gemini API : requiert VERTEX AI
Pour Google aujourd’hui, la réponse courte est simple : tu continues à effectuer le fine-tuning de tes modèles Gemini via Vertex AI,
mais le client recommandé devient désormais le Google Gen AI SDK (« google.genai »), et non plus les anciens namespaces
vertexai.* qui sont en phase de dépréciation et vont disparaître des prochaines versions du SDK Vertex AI (vertexai.generative_models, vertexai.language_models, etc.).
Note GeminI With the deprecation of Gemini 1.5 Flash-001 in May 2025, we no longer have a model available which supports fine-tuning in the Gemini API, but it is supported in Vertex AI. ref : https://ai.google.dev/gemini-api/docs/model-tuning
En résumé il faut passer par VERTEX AI https://console.cloud.google.com/vertex-ai/studio/multimodal
Note : Vertex AI est un service payant (ou nécessite un compte de facturation actif même pour le tiers gratuit)
Gemini 1.5 Flash-001, aucun modèle disponible via la Gemini API seule ne supporte encore le fine-tuning ;ce support a été déplacé vers Vertex AI, où il reste pleinement disponible.En pratique, pour adapter un modèle comme
gemini-2.5-flash à ce cas d’usage (génération de diagrammes Mermaid, classification, réécriture de texte, etc.), il faut donc créer un tuning job sur Vertex AI : préparer un dataset d’entraînement au format JSONL dans Cloud Storage, puis lancer le job soit depuis la console Vertex AI Studio,soit de manière programmatique via le Google Gen AI SDK (
client.tunings.tune(...)), soit via l’API REST Vertex AI.Le Google Gen AI SDK fournit une parité fonctionnelle avec les anciens modules de génération de Vertex AI, tout en unifiant l’accès aux modèles Gemini et aux fonctionnalités de tuning, d’évaluation et de déploiement. Pour un projet nouveau ou une mise à jour de code existant, la recommandation est donc de migrer le code de vertexai.* vers google.genai en s’appuyant sur le guide officiel de migration https://docs.cloud.google.com/vertex-ai/generative-ai/docs/deprecations/genai-vertexai-sdk , afin de rester compatible avec les futures versions du SDK et de bénéficier des nouvelles capacités.Au final voir exemple du script https://github.com/blue101010/diagram-llm2/blob/main/gemini_fine_tune/perform_inference_vertex.py
Obtenir votre clé API Google AI Studio (tests directs sans fine-tuning)
La clé Google AI Studio est gratuite et prend seulement quelques minutes à créer :
| 1 | Rendez-vous sur https://aistudio.google.com/api-keys et connectez-vous avec votre compte Google |
| 2 | Cliquez sur Créer un projet |
| 3 | Cliquez sur “Créer une clé” → Copiez immédiatement la clé affichée |
3. Installation en 5 minutes
Ouvrez votre terminal et exécutez :
# Cloner le repository
git clone https://github.com/blue101010/diagram-llm2.git
cd diagram-llm2
# Créer et activer l'environnement virtuel
python -m venv venv
#Activer venv (linux)
source venv/bin/activate
# Windows:
#venv\Scripts\activate.bat
#venv\Scripts\Activate.ps1
venv/Scripts/activate
# Installer les dépendances
pip install -r requirements.txt
#confirmer le .gitignore pointe .env pour éviter tout commit de clé
# Configurer votre clé API et confirmer le .git
cp .env.example .env
# Éditez .env et ajoutez :
GEMINI_API_KEY=votre_clé_iciVérifier l’installation :
python -c 'from google import genai; print("✅ Installation OK!")'4. Structure du projet
Voici l’architecture du projet et le rôle de chaque composant :
diagram-llm2/
├── synthetic_dataset_generator/ # 🏭 Génère les paires prompt→diagramme
├── validator/ # ✅ Vérifie la syntaxe Mermaid
├── previewer/ # 👁️ Visualise les diagrammes générés
├── gemini_fine_tune/ # ☁️ Fine-tuning via API Google (gemma et Gemmini)
├── phi_4_fine_tune/ # 🖥️ Fine-tuning local avec LoRA (requiert GPU)
├── generated_synthetic_datasets/ # 📦 Datasets générés
├── diagram_generation_on_cpu # ☁️ Fine-tuning local, sans GPU mais CPU Qwen2.5-1.5B
├── images/ # 🖼️ Captures d'écran et exemples
├── .env.example # 🔐 Template de configuration
└── requirements.txt # 📋 Dépendances Python| Module | Quand l’utiliser | Commande principale |
|---|---|---|
synthetic_dataset_generator |
Créer vos données d’entraînement | python generator.py |
validator |
Tester le taux de succès | Ouvrir index.html |
previewer |
Inspecter visuellement | python -m http.server 3000 |
gemini_fine_tune |
Fine-tuning cloud (recommandé) | Notebook Jupyter |
phi_4_fine_tune |
Fine-tuning local GPU | Notebook Jupyter |
5. Générer votre dataset synthétique
Le cœur de diagram-llm2 est la génération de paires prompt→diagramme de haute qualité. Le générateur utilise la documentation officielle Mermaid pour créer des exemples variés et syntaxiquement corrects.
Types de diagrammes supportés
- 📊 Flowcharts – Organigrammes et processus
- 🔄 Sequence diagrams – Interactions entre composants
- 📐 Class diagrams – Architecture orientée objet
- 📅 Gantt charts – Planification de projets
- 🏗️ Architecture diagrams – Infrastructure système
- 📋 Kanban boards – Gestion de tâches
- 🌳 Gitgraph – Historique de branches
- ⏱️ Timeline – Chronologies
- 🏢 C4 diagrams – Architecture logicielle
Exemple de données générées
Prompt d’entrée :
Generate a Kanban diagram with columns 'To Do' (id: c1), 'Doing' (id: c2),
'Code Review' (id: c3), and 'Deployed' (id: c4). Add 'Fix Bug #123' (id: bug123)
to 'Doing'. Add 'Review Pull Request #45' (id: pr45) to 'Code Review'.Sortie Mermaid attendue :
kanban
c1[To Do]
c2[Doing]
bug123[Fix Bug #123]
c3[Code Review]
pr45[Review Pull Request #45]
c4[Deployed]
deploy21[Deploy Version 2.1]6. Fine-tuning : Gemini vs Phi-4
Deux approches sont disponibles selon vos ressources :
| Critère | ☁️ Gemini/Gemma (Cloud) | 🖥️ Phi-4 (Local) |
|---|---|---|
| Matériel requis | Aucun (API cloud) | GPU 16 Go+ VRAM |
| Coût | Gratuit (quota limité) | Électricité uniquement |
| Performance | ~94% compilation | ~89% compilation |
| Temps de fine-tuning | ~30 min à 1h pour Gemini 2.5 ou 3.0 (géré par Google) a 3 à 8h pour Gemma | ~2-4 heures |
| Contrôle | Limité (hyperparamètres) | Total (architecture, LoRA) |
| Déploiement | Via API Google | Self-hosted |

Option A2 : Fine-tuning Gemma-3-27b-it(Recommandé pour débuter, moins performant que gemini-3-flash)
Gemma-3-27b-it, en janvier 2026 est gratuit sur une base de 14400 RPD (request per Day) contre seulement 20 RPD pour gemini-3-flash-preview (très peu de tests possibles gratuitement…)
Option A1 : Fine-tuning Gemini
Le fine-tuning Gemini utilise l’API GenAI SDK. Voici le code essentiel simplifié (voir les scripts complets sur repository Github) :
# gemini_fine_tune/tuning_job.py
from google import genai
from google.genai import types
import os
# Configuration
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Charger le dataset au format JSONL
# Format: {"text_input": "prompt", "output": "code mermaid"}
training_dataset = types.TuningDataset(
inline_data=types.InlineData(
file_path="data/mermaid_training.jsonl"
)
)
# Lancer le fine-tuning (ici exemple ancien de principe avec gemini-2.0-flash-001)
tuning_job = client.tunings.create(
base_model="models/gemini-2.0-flash-001",
training_dataset=training_dataset,
config=types.CreateTuningJobConfig(
epoch_count=3, # 2-5 recommandé
learning_rate_multiplier=1.0, # 0.5-2.0
tuned_model_display_name="mermaid-generator-v1"
)
)
print(f"Job ID: {tuning_job.name}")
print(f"État: {tuning_job.state}")Format du fichier JSONL :
{"text_input": "Create a flowchart for user login", "output": "graph TD\n A[Start] --> B[Enter credentials]\n B --> C{Valid?}\n C -->|Yes| D[Dashboard]\n C -->|No| B"}
{"text_input": "Draw a sequence diagram for API call", "output": "sequenceDiagram\n Client->>Server: POST /api/data\n Server-->>Client: 200 OK"}Option B : Fine-tuning Phi-4 avec LoRA
Pour un contrôle total et un déploiement self-hosted :
# phi_4_fine_tune/train.py
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
# Charger le modèle de base
model_name = "microsoft/phi-4"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Configuration LoRA (Parameter-Efficient Fine-Tuning)
lora_config = LoraConfig(
r=16, # Rang de la décomposition (8-64)
lora_alpha=32, # Facteur de scaling (généralement 2*r)
target_modules=["q_proj", "v_proj"], # Couches à adapter
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# Appliquer LoRA au modèle
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: "trainable params: 4,194,304 || all params: 14,000,000,000 || trainable%: 0.03%"
# Configuration de l'entraînement
training_args = TrainingArguments(
output_dir="./phi4-mermaid-lora",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
warmup_steps=100,
logging_steps=10,
save_strategy="epoch",
fp16=True, # ou bf16=True selon votre GPU
)
# Lancer l'entraînement
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
tokenizer=tokenizer,
max_seq_length=2048,
)
trainer.train()7. Valider vos diagrammes
Le module validator vous permet de tester le taux de compilation des diagrammes générés :
1. Ouvrez validator/index.html directement dans votre navigateur
2. Chargez votre fichier JSON contenant les diagrammes générés
3. Le validateur affiche le taux de succès et les erreurs détaillées
Pour la prévisualisation visuelle :
cd previewer
python -m http.server 3000
# Ouvrez http://localhost:3000 dans votre navigateur8. Cas pratiques
Cas 1 : Générer un diagramme d’architecture
# Utilisation du modèle fine-tuné Gemini
from google import genai
import os
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
prompt = """Create an architecture diagram with:
- Group 'vpc' (cloud icon) containing:
- API Gateway (server icon)
- Lambda Function (server icon)
- S3 Bucket (disk icon)
- External Database outside VPC
- Connect API Gateway to Lambda to S3
- Connect Lambda to External Database"""
response = client.models.generate_content(
model="tunedModels/mermaid-generator-v1", # Votre modèle fine-tuné
contents=prompt
)
print(response.text)Sortie :
architecture-beta
group vpc(cloud)[VPC Network]
service api_gw(server)[API Gateway] in vpc
service lambda_func(server)[Function] in vpc
service s3_bucket(disk)[Storage Bucket] in vpc
service external_db(database)[External DB]
api_gw:R --> L:lambda_func
lambda_func:B --> T:s3_bucket
lambda_func:R --> L:external_dbCas 2 : Diagramme de séquence pour une API REST
prompt = """Generate a sequence diagram for JWT authentication:
1. User sends login request with credentials
2. Server validates and returns JWT token
3. User makes authenticated request with token
4. Server validates token and returns data"""
response = client.models.generate_content(
model="tunedModels/mermaid-generator-v1",
contents=prompt
)
print(response.text)Sortie :
sequenceDiagram
participant User
participant Server
participant Database
User->>Server: POST /login {credentials}
Server->>Database: Validate user
Database-->>Server: User valid
Server-->>User: 200 OK {jwt_token}
User->>Server: GET /api/data (Authorization: Bearer token)
Server->>Server: Validate JWT
Server->>Database: Fetch data
Database-->>Server: Data
Server-->>User: 200 OK {data}Cas 3 : Intégration dans une documentation Markdown
def generate_doc_diagram(description: str, model_id: str) -> str:
"""Génère un diagramme et le formate pour Markdown."""
response = client.models.generate_content(
model=model_id,
contents=description
)
mermaid_code = response.text.strip()
# Format Markdown pour GitHub/GitLab
return f"""```mermaid
{mermaid_code}
```"""
# Utilisation
doc_section = generate_doc_diagram(
"Flowchart for CI/CD pipeline with build, test, and deploy stages",
"tunedModels/mermaid-generator-v1"
)
# Écrire dans un fichier README
with open("README.md", "a") as f:
f.write("\n## Architecture\n\n")
f.write(doc_section)Cas 4 : Génération batch pour documentation technique
import json
from concurrent.futures import ThreadPoolExecutor
diagrams_to_generate = [
{"name": "auth_flow", "prompt": "Flowchart for user authentication"},
{"name": "data_pipeline", "prompt": "Flowchart for ETL data pipeline"},
{"name": "microservices", "prompt": "Sequence diagram for microservices communication"},
{"name": "db_schema", "prompt": "ER diagram for e-commerce database"},
]
def generate_diagram(item):
response = client.models.generate_content(
model="tunedModels/mermaid-generator-v1",
contents=item["prompt"]
)
return {
"name": item["name"],
"prompt": item["prompt"],
"mermaid": response.text.strip()
}
# Génération parallèle
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(generate_diagram, diagrams_to_generate))
# Sauvegarder
with open("generated_diagrams.json", "w") as f:
json.dump(results, f, indent=2)
print(f"✅ {len(results)} diagrammes générés")9. Dépannage
❌ Erreur : “Invalid API key”
# Vérifiez que la variable d'environnement est définie
echo $GEMINI_API_KEY
# Si vide, exportez-la
export GEMINI_API_KEY="votre_clé"
# Ou ajoutez dans votre .bashrc/.zshrc
echo 'export GEMINI_API_KEY="votre_clé"' >> ~/.bashrc❌ Erreur : “CUDA out of memory” (Phi-4)
# Option 1 : Réduire la taille du batch
per_device_train_batch_size=2 # au lieu de 4
# Option 2 : Activer gradient checkpointing
training_args = TrainingArguments(
...
gradient_checkpointing=True,
)
# Option 3 : Utiliser la quantification 4-bit (QLoRA)
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
)❌ Diagrammes générés toujours invalides
- Vérifiez la qualité de votre dataset (utilisez le validator avant le fine-tuning)
- Augmentez le nombre d’époques (3 → 5)
- Augmentez la taille du dataset (ajoutez 500+ exemples)
- Vérifiez le format JSONL (une ligne = un objet JSON complet)
❌ Fine-tuning Gemini bloqué à “PENDING”
# Vérifier le statut
job = client.tunings.get(name="tunedModels/votre-job-id")
print(f"État: {job.state}")
print(f"Erreur: {job.error}") # Si applicable
# Les jobs peuvent prendre 15-60 min selon la charge📚 Workflow principal du projet diagram-llm2

🔄 Workflow principal du projet diagram-llm2
Chaîne complète de génération : création du dataset, validation, prévisualisation, fine‑tuning puis inférence pour produire des diagrammes Mermaid fiables.
Chaque étape est automatisée afin de contrôler la qualité, stabiliser la syntaxe et réduire le coût d’utilisation des modèles lourds.
📚 Ressources complémentaires
- 🔗 Repository GitHub diagram-llm2
- 📖 Documentation officielle Mermaid
- 📝 Documentation PEFT/LoRA (Hugging Face)
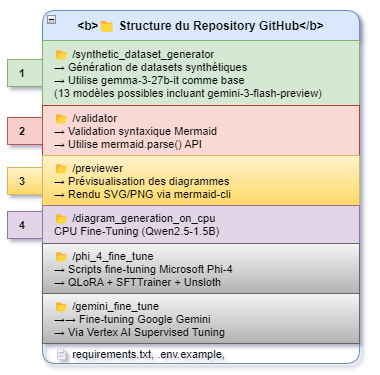
📁 Structure du repository
- 1 —
/synthetic_dataset_generator: génération de jeux de données synthétiques à partir de prompts, basée sur un modèle LLM (famille gemma / gemini). - 2 —
/validator: validation syntaxique des diagrammes Mermaid (parseur dédié) pour garantir des sorties exploitables. - 3 —
/previewer: prévisualisation des diagrammes en SVG/PNG via la CLI Mermaid, utile pour le contrôle qualité visuel. - 4 —
/diagram_generation_on_cpu& fine-tune dirs : scripts de fine‑tuning et d’inférence sur différents LLM (Qwen2.5, Phi‑4, Gemini) avec techniques PEFT/LoRA.
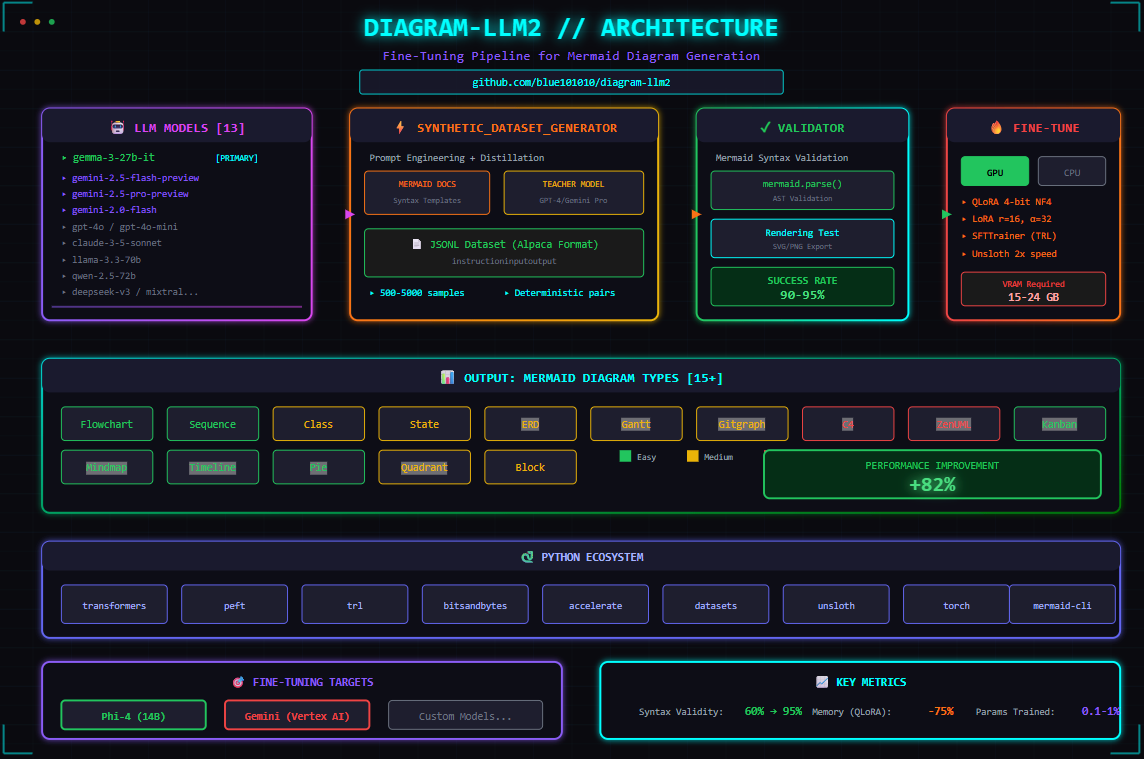
🧠 Architecture LLM & génération de diagrammes Mermaid
Vue d’ensemble du pipeline : génération de datasets synthétiques, validation, fine-tuning GPU/CPU
et production automatisée de diagrammes Mermaid pour le projet
diagram-llm2.